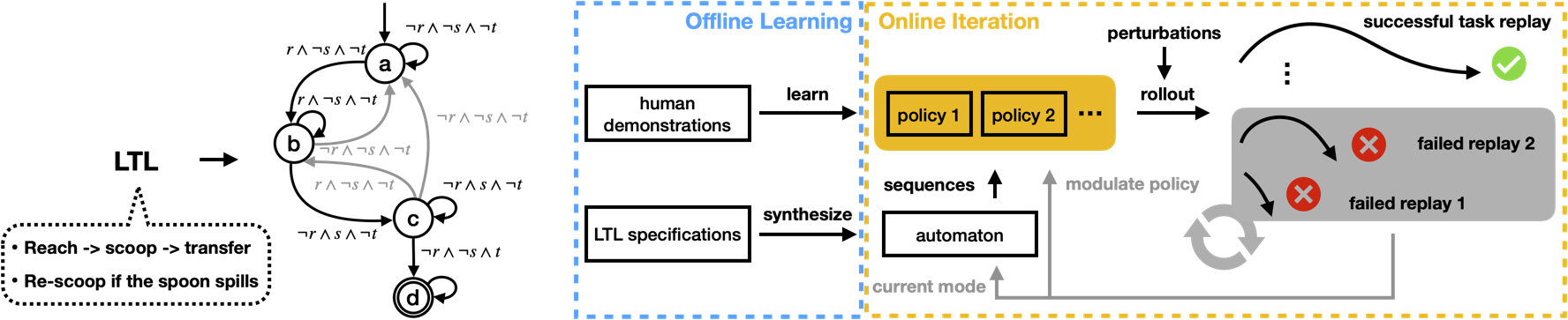
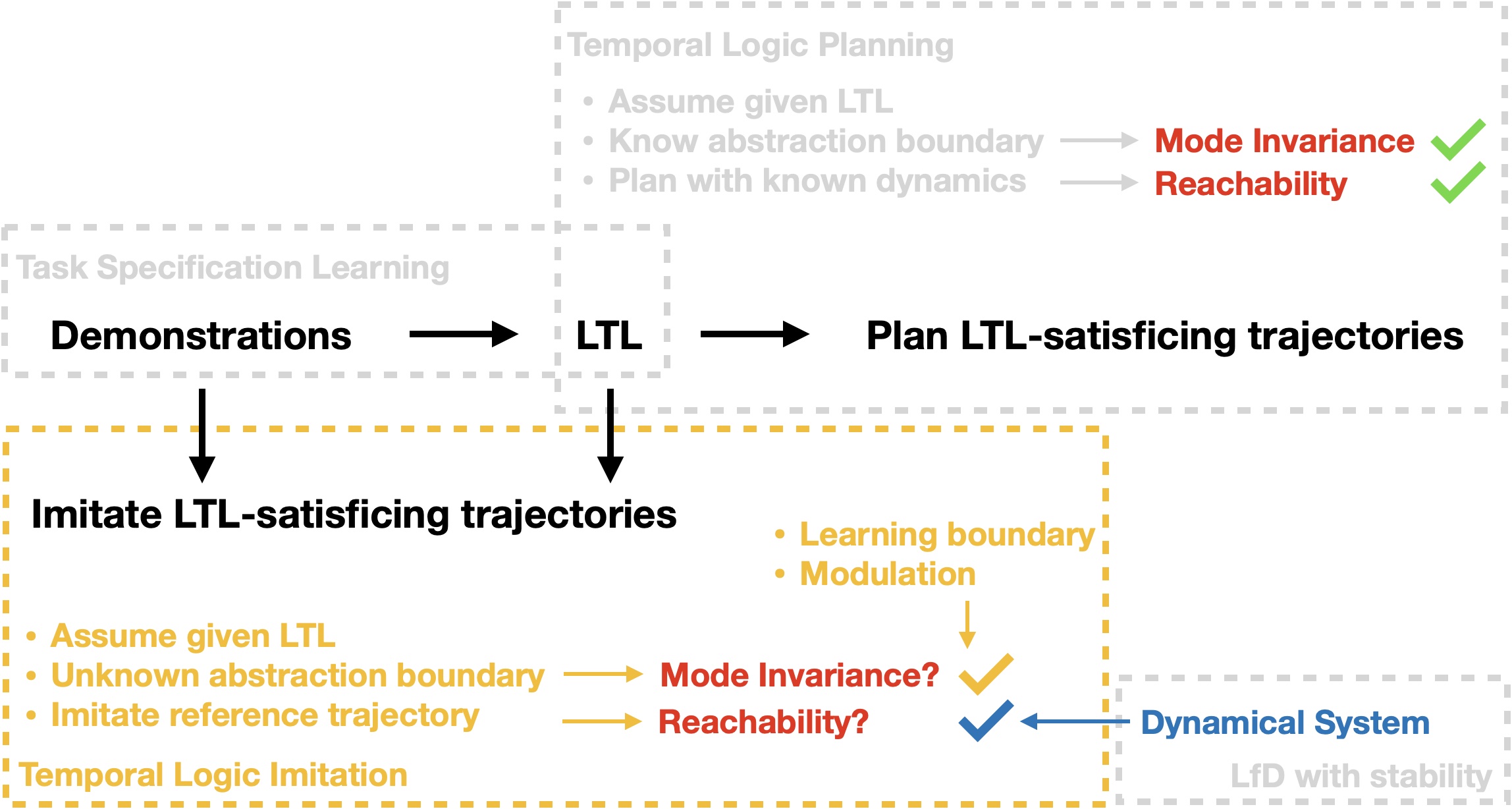
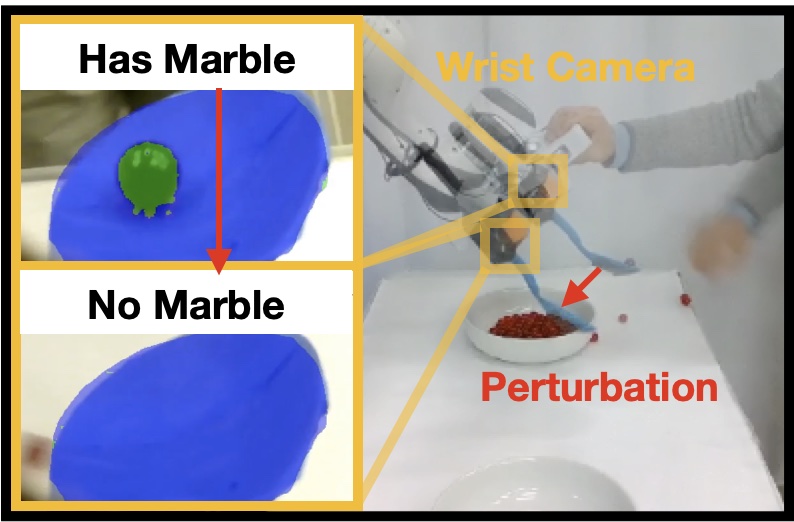
Abstract
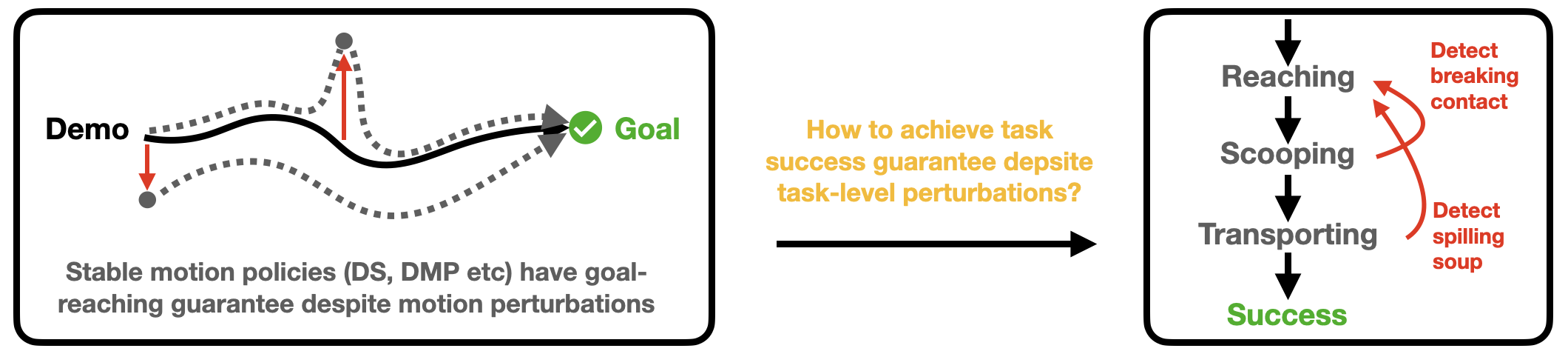
Learning from demonstration (LfD) has succeeded in tasks featuring a long time horizon. However, when the problem complexity also includes human-in-the-loop perturbations, state-of-the-art approaches do not guarantee the successful reproduction of a task. In this work, we identify the roots of this challenge as the failure of a learned continuous policy to satisfy the discrete plan implicit in the demonstration. By utilizing modes (rather than subgoals) as the discrete abstraction and motion policies with both mode invariance and goal reachability properties, we prove our learned continuous policy can simulate any discrete plan specified by a linear temporal logic (LTL) formula. Consequently, an imitator is
robust to both task- and motion-level perturbations and guaranteed to achieve task success.