Interactive Robotics Lab / CSAIL
Massachusetts Institute of Technology
Abstract
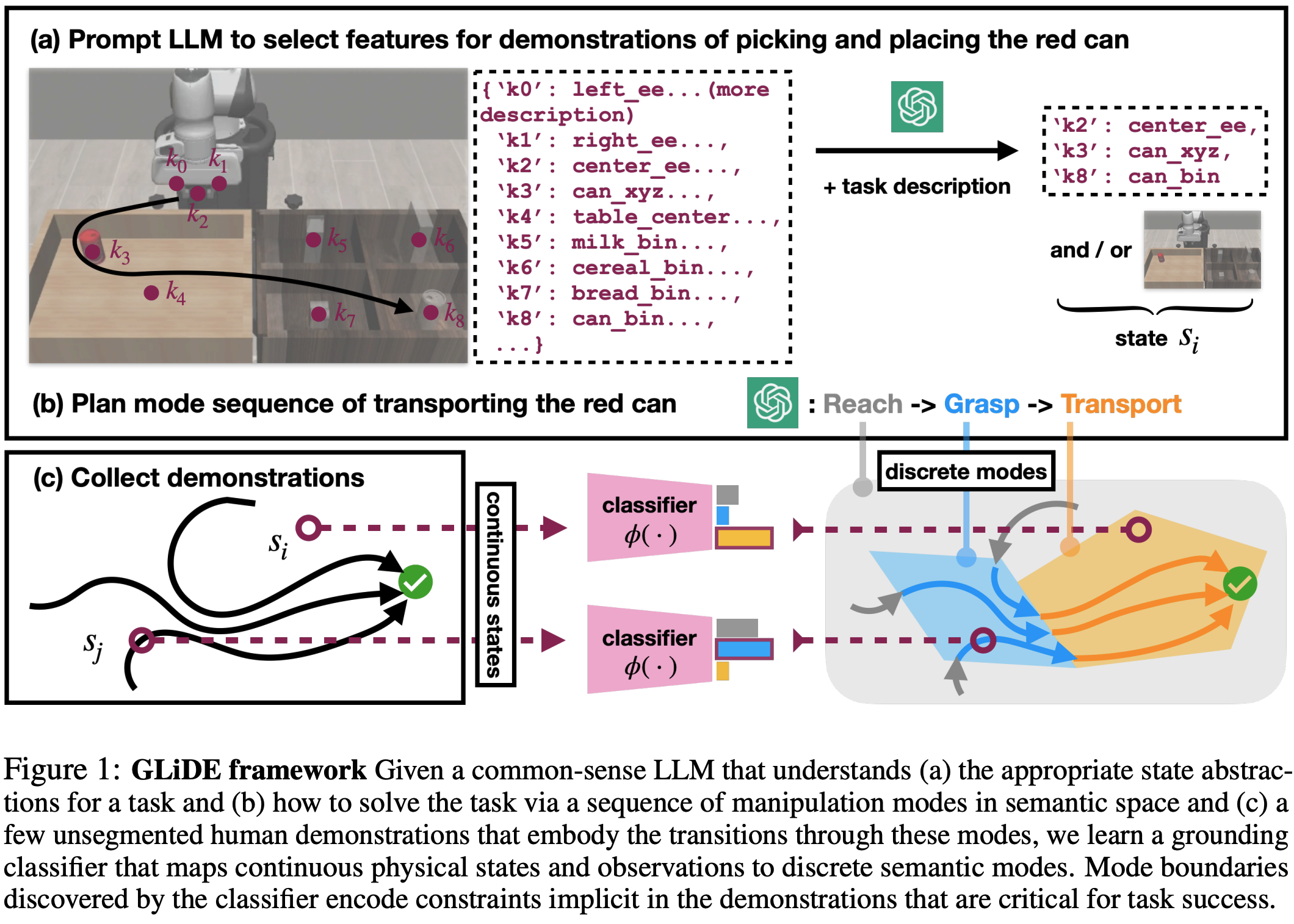
Grounding the common-sense reasoning of Large Language Models (LLMs) in physical domains remains a pivotal yet unsolved problem for embodied AI. Whereas prior works have focused on leveraging LLMs directly for planning in symbolic spaces, this work uses LLMs to guide the search of task structures and constraints implicit in multi-step demonstrations. Specifically, we borrow from manipulation planning literature the concept of mode families, which group robot configurations by specific motion constraints, to serve as an abstraction layer between the high-level language representations of an LLM and the low-level physical trajectories of a robot. By replaying a few human demonstrations with synthetic perturbations, we generate coverage over the demonstrations' state space with additional successful executions as well as counterfactuals that fail the task. Our explanation-based learning framework trains an end-to-end differentiable neural network to predict successful trajectories from failures and as a by-product learns classifiers that ground low-level states and images in mode families without dense labeling. The learned grounding classifiers can further be used to translate language plans into reactive policies in the physical domain in an interpretable manner. We show our approach improves the interpretability and reactivity of imitation learning through 2D navigation and simulated and real robot manipulation tasks.
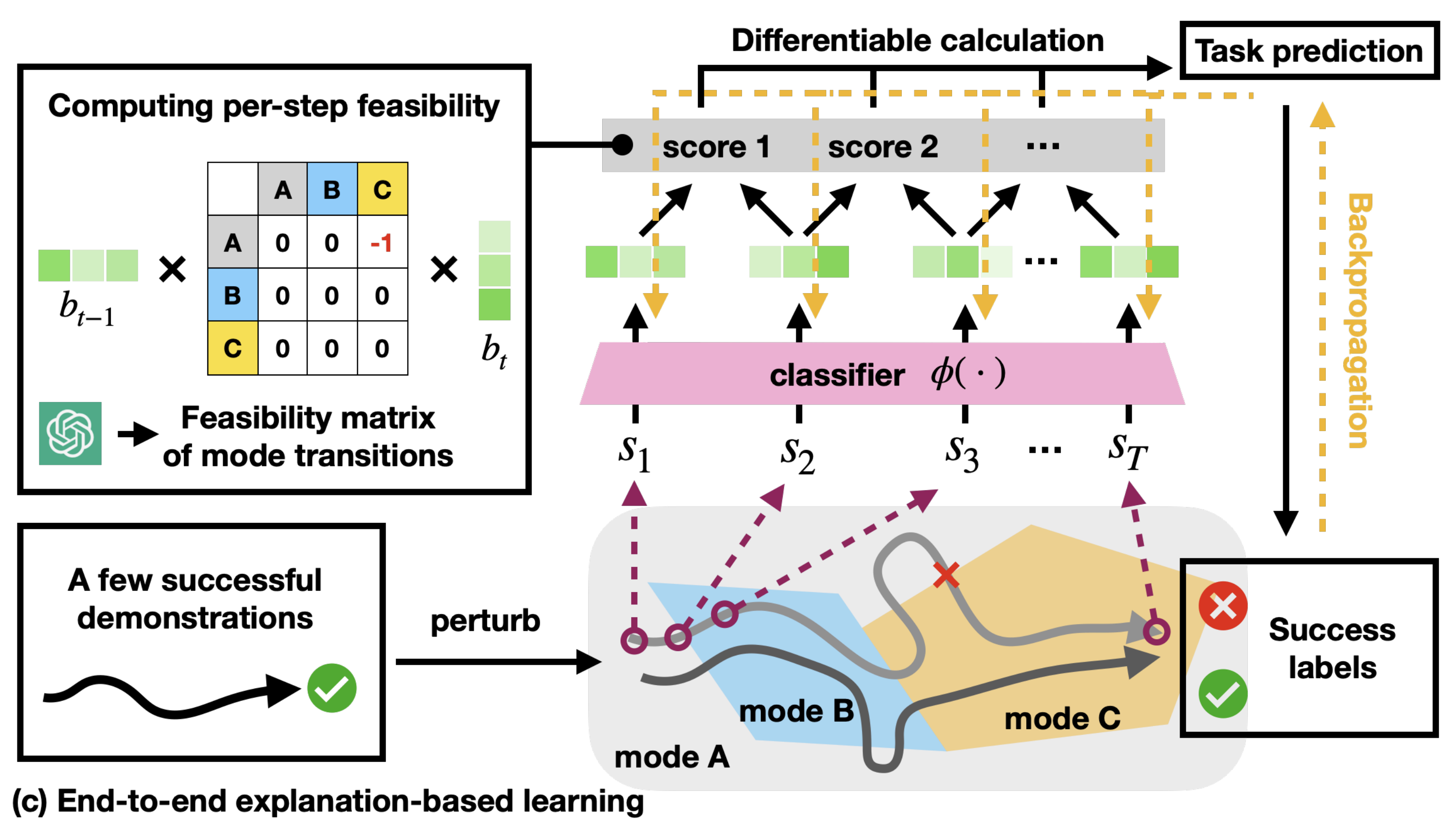
By prompting LLM to describe successful executions in terms of valid mode transitions via a feasibility
matrix, and augmenting demonstrations with counterfactual perturbations, we train a fully differentiable
pipeline to predict task execution outcomes. Since the fully-differentiable pipeline calculates overall
trajectory success based on mode classification results of individual states, we can learn classifiers that
achieve grounding as a by-product of predicting the overall task execution.
Experiments
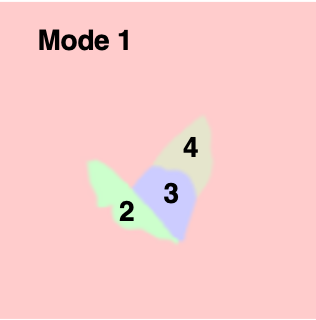
Learned Mode Partitions of Configuration Space for 2D Navigation Tasks
The navigation domain serves as a 2D abstraction of the modal structure for multi-step manipulation tasks, where
each polygon represents a different mode with its boundary showing the constraint. The goal is to traverse through
the sequence consecutively as demonstrated until reaching the last colored polygon (e.g. mode 1 -> 2 -> 3 -> 4 -> 5). Mode transitions violating the demonstrated temporal ordering will lead to task failure (e.g. mode 1 -> 3/4/5).
(a) Demonstrations and ground truth modes
(b) Grounding learned by GLiDE
(c) GLiDE without counterfactual data
(d) GLiDE with incorrect number of modes
(e) Baseline: similarity-based clustering
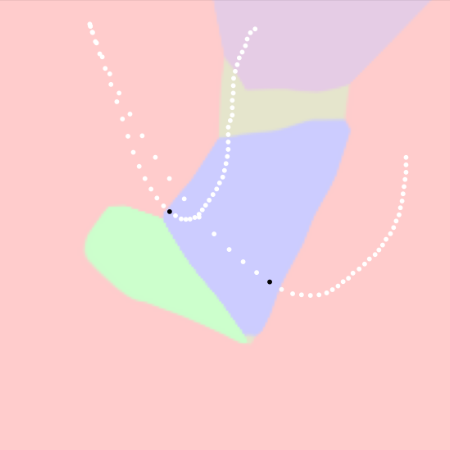
Learned Mode Partitions Explain Why Some Perturbed Trajectories Succeed While Others Fail
Learned classifier explains success trajectories by checking if all transitions incur 0 cost (shown by the whiteness of dots). It also explains failure trajectories by checking if there exists at least one invalid transition (indicated by the blackness of dots).
The learned grounding classifier can be used to segment whole demonstrations into sub-sequences for each mode, for which we extract the sub-goal (the average crossing point at each boundary) for each mode. Additionally, the explicit mode partitions allow us construct a potential flow controller for each mode that directs the system to reach each sub-goal without leaving the current mode prematurely. Should the execution be derailed by external perturbations, planning without and with the learned mode boundaries can lead to execution failures (left) or successes (right), respectively.
Planning without learned grounding leads to failures due to invalid mode transitions
Planning with learned grounding leads to successful recovery that obeys mode constraints
Self-Supervised Data Collection for 2D Navigation Tasks
To generate the data for training the grounding classifier, we first collect a few successful demonstrations from humans. We then apply synthetic perturbations to demonstration replays to generate additional successful trajectories and failing counterfactuals. Assuming an automatic reset mechanism and a labeling function that decides the trajectory execution outcome, we can collect a large dataset without humans in the loop.
Data Collection Setup
Human demonstrations: Mode 1 -> 2 -> 3 -> 4 -> 5. Invalid mode transitions: 1 -> 3 or 1 -> 4 or 1 -> 5
Add synthetic perturbations to demonstration replays with auto-labeling and auto-reset
Given a dataset of perturbed replays with only sparse labels, we learn a classifier that maps image observations to the their corresponding modes shown by distinct colors.
Learned Grounding Classifier Enables Replanning for 2D Navigation Tasks
Once we learn the classifier, we can use it to generate a mode-informed policy that replans when a perturbation would lead the original policy to incur an invalid mode transition (e.g., white directly to blue/yellow/red)
Naive policy: without knowledge of the modes, the robot simply continues after perturbation which can lead to invalid mode transitions.
Mode-conditioned policy: By accurately recognizing the underlying modes, our method allows for recovery when perturbations cause unexpected mode transitions.
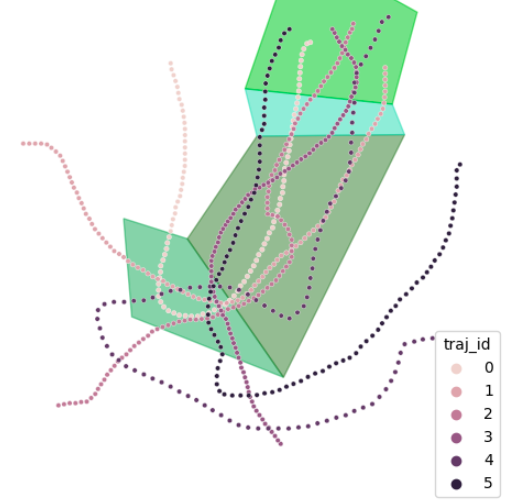
Learned Mode Segmentation of Demonstrations for Robosuite Manipulation Tasks
(Left) We manually set a ground truth based on RoboSuite state information to
benchmark our learned mode segmentation, visualized in the left figure. Can Task: pick up the can and place it in the bottom-right
bin. Lifting Task: pick up the block above a specified
height. Square Peg Task: pick up the square nut and place it
on the square peg. You can view pictures of all of the classification results here.
(Below) To show the learned grounding can facilitate planning using LLMs, we
apply perturbations to Behavioral Cloning (BC) rollouts below. BC performance drops off
significantly with perturbations, but our method generally recovers better after the robot drops
the can as the robot will be directed to pick up the can again.
Learned Grounding facilitates replanning with LLMs to improve execution success rate for RoboSuite Tasks
Behavior cloning (BC) rollouts: 93% success
BC rollouts (perturbed): 20% success
Mode-conditioned BC (perturbed): 40% success
Learned Grounding Classifier Enables Replanning for Real-World Scooping Task
A scooping task that requires the robot to transport at least a marble from one bowl to the other. Given external perturbations, the robot may drop marbles during transport, leading to a failed execution. When an imitation policy does not pay attention to the classified modes (shown on the right in the video), it cannot recover from such failures. In constrast, a mode-conditioned policy can replan and recover from such perturbations.
Mode-agnostic BC cannot recover from task-level perturbations (e.g. dropping all marbles)
Mode-conditioned BC enabled by the learned grounding can leverage LLM to replan
Related Works - Prior work that GLiDE extends by learning instead of engineering sensor models
We present a continuous motion imitation method that can provably satisfy any discrete plan specified by a
Linear Temporal Logic (LTL) formula. Consequently, the imitator is robust to both task- and motion-level
disturbances and guaranteed to achieve task success.