Computer Science and Artificial Intelligence Laboratory (CSAIL)
Massachusetts Institute of Technology
Abstract
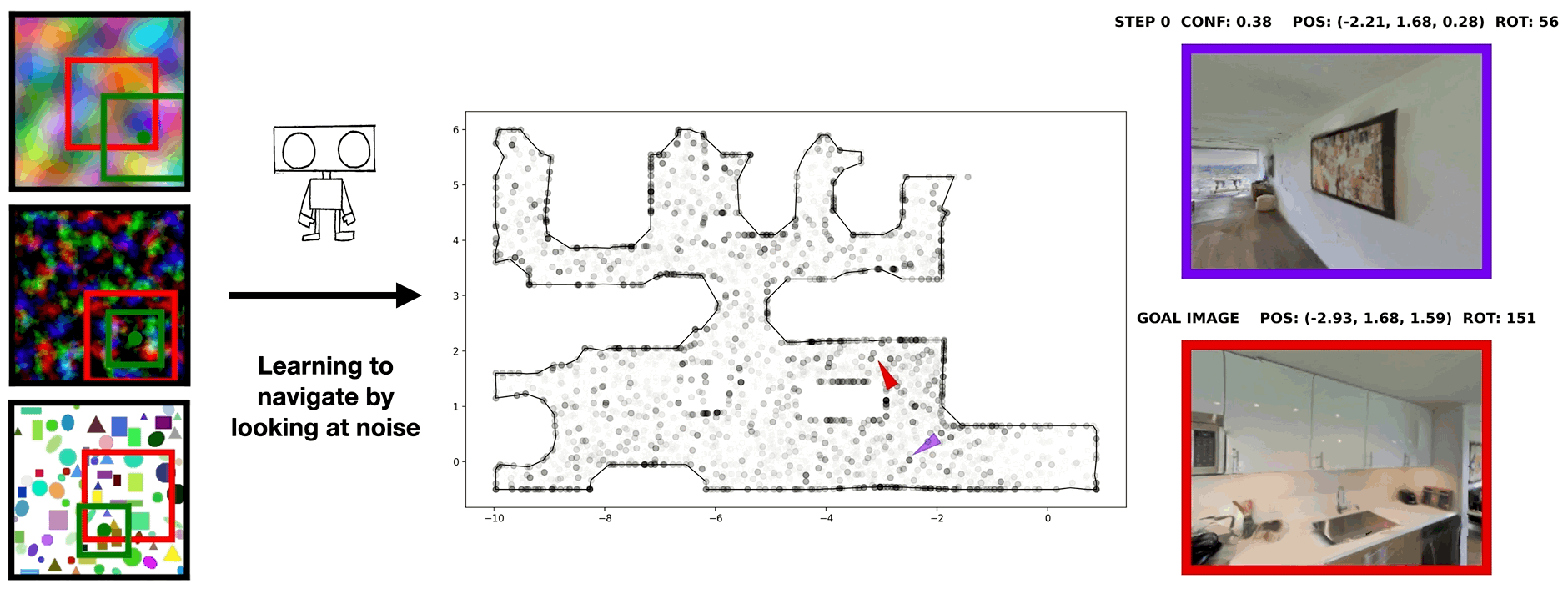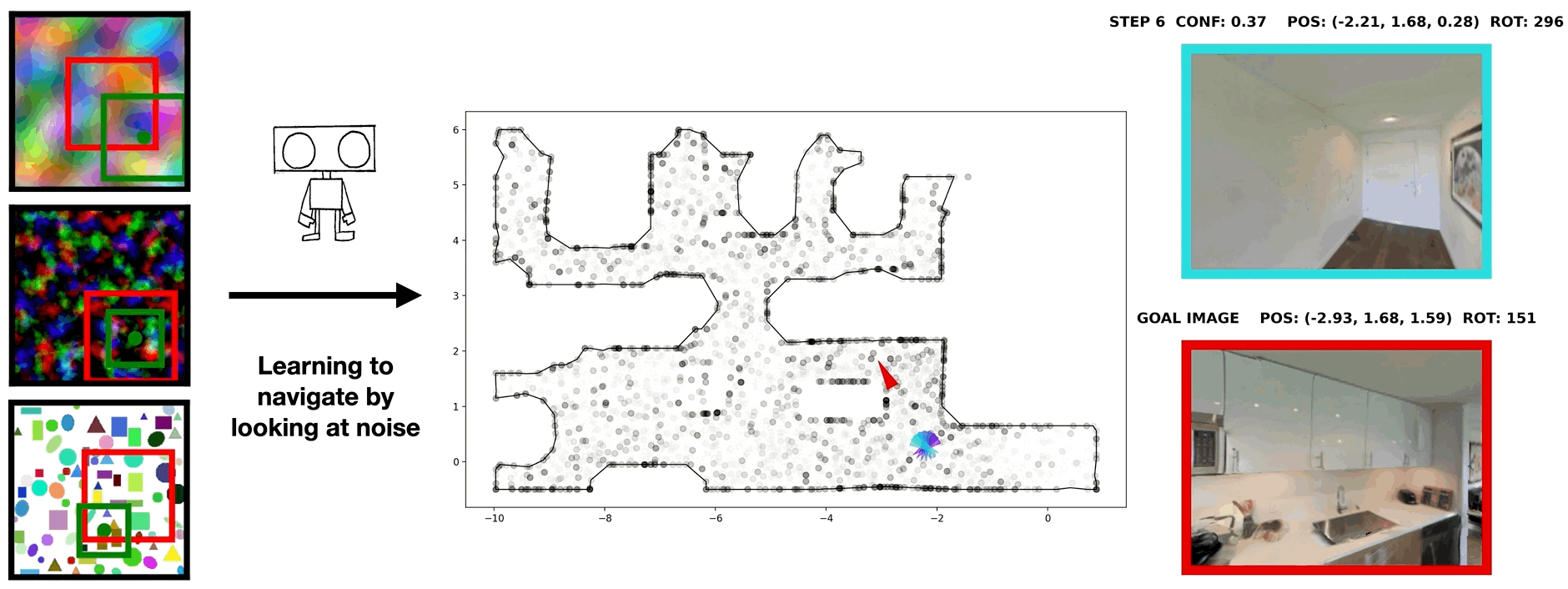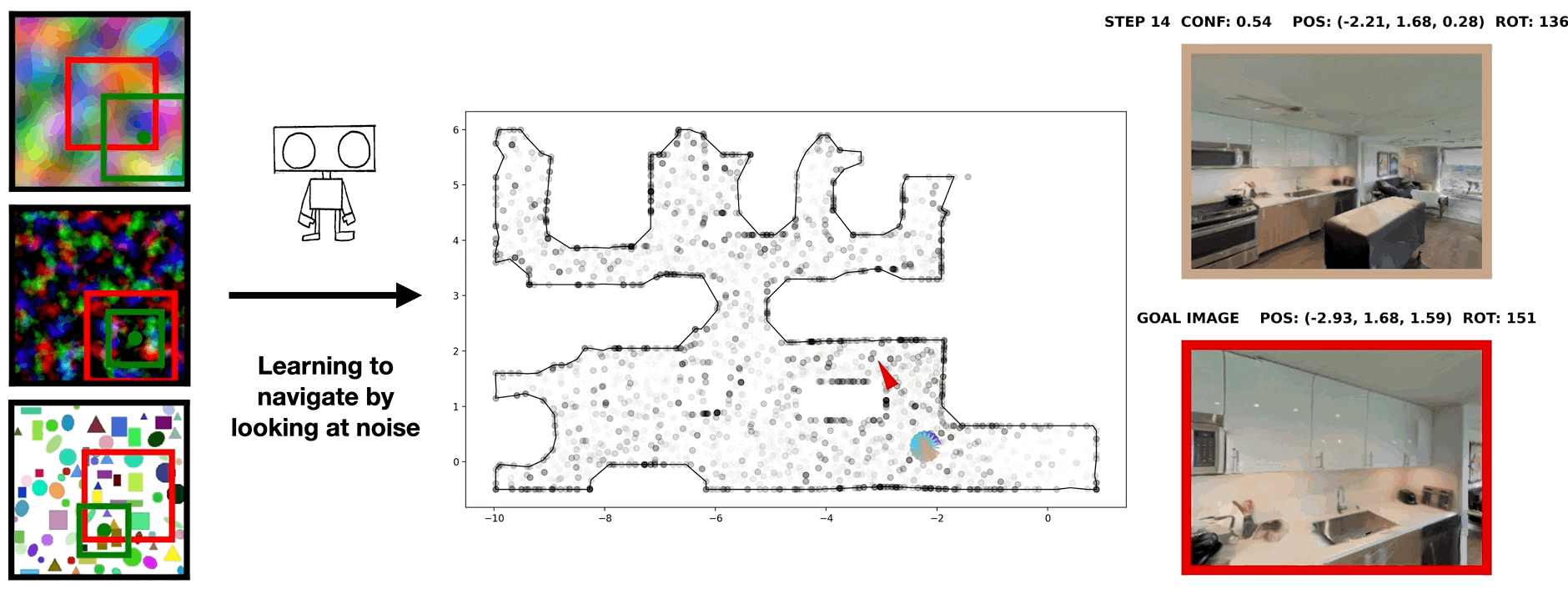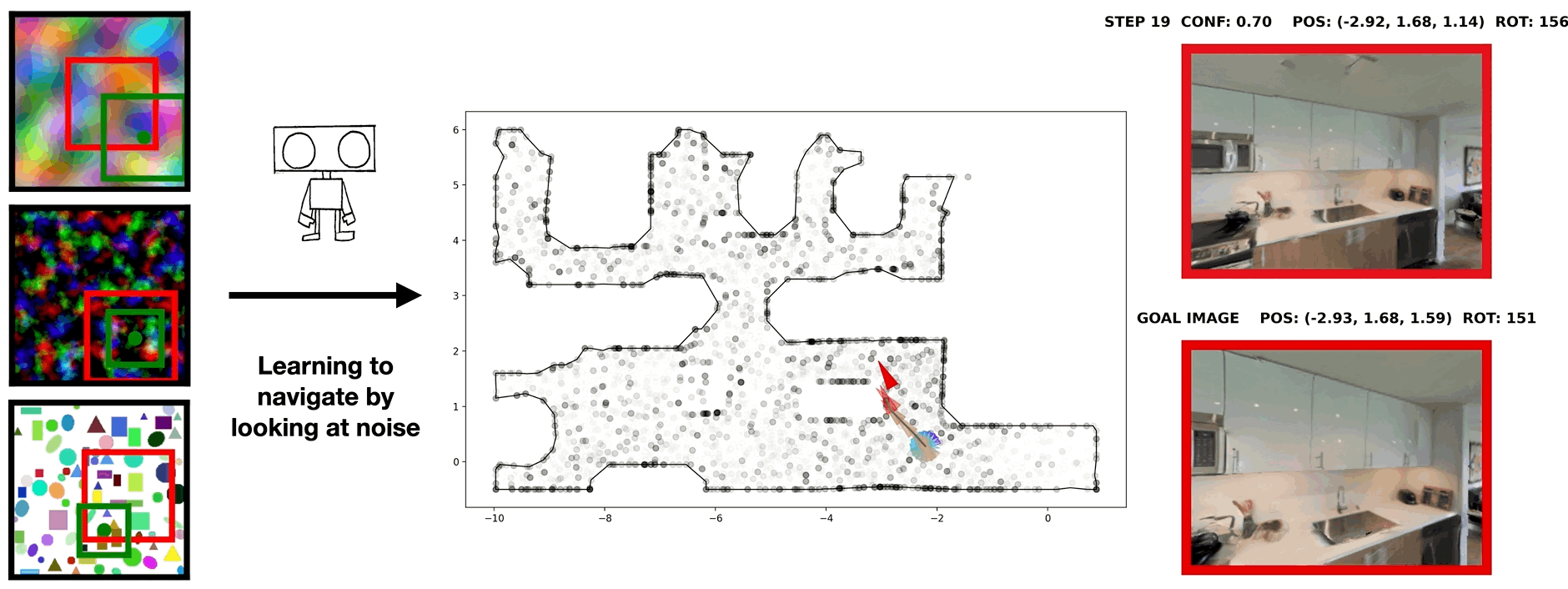
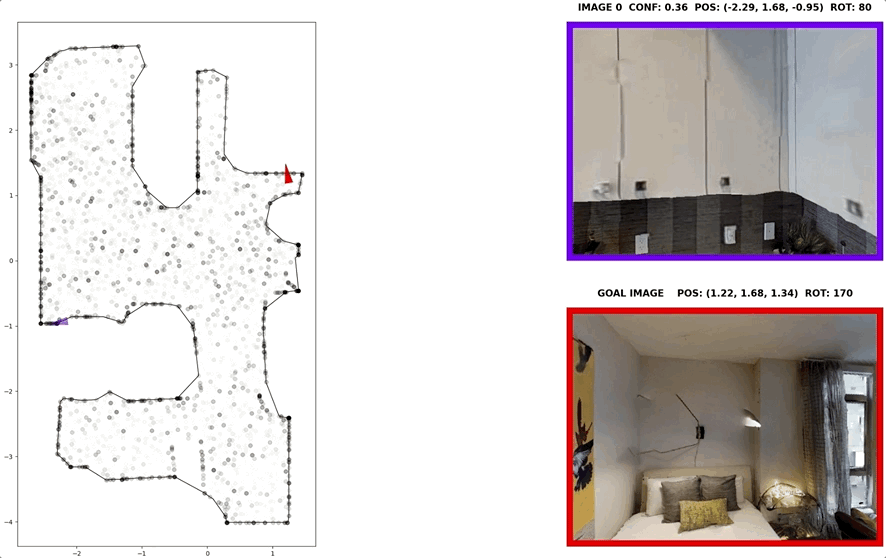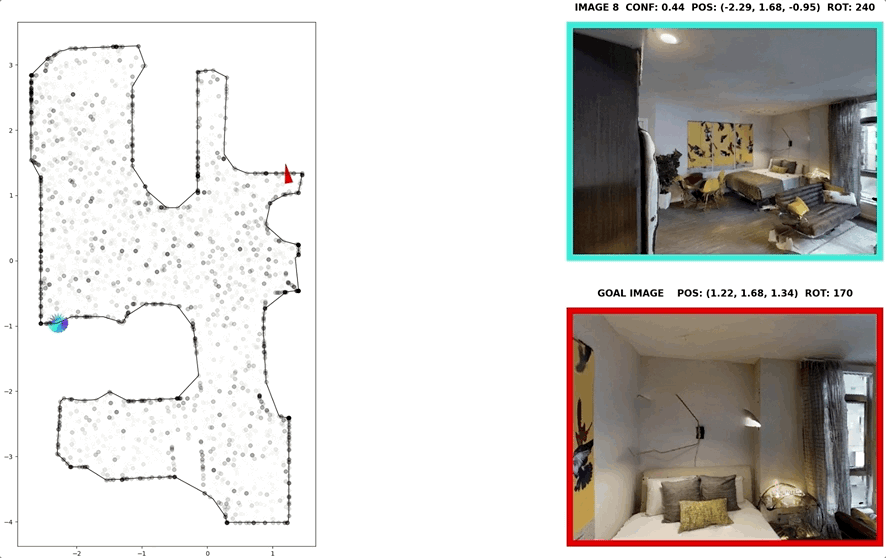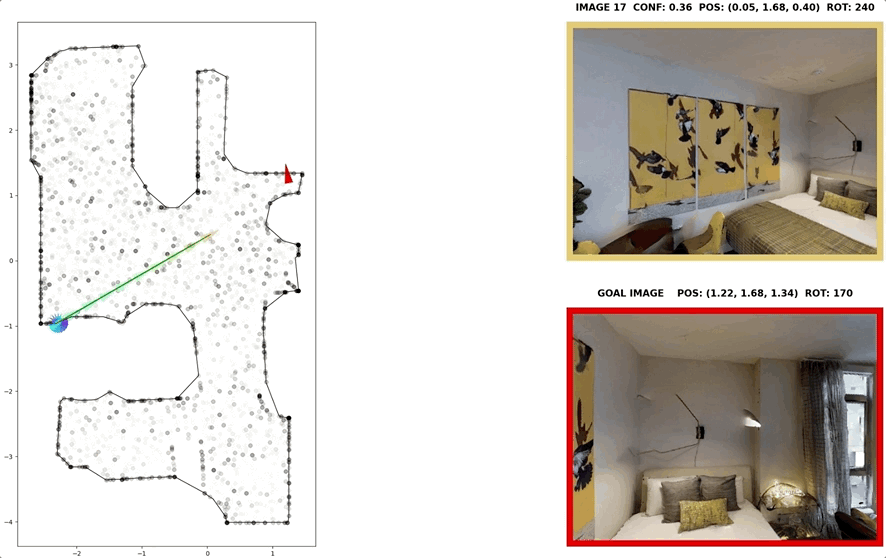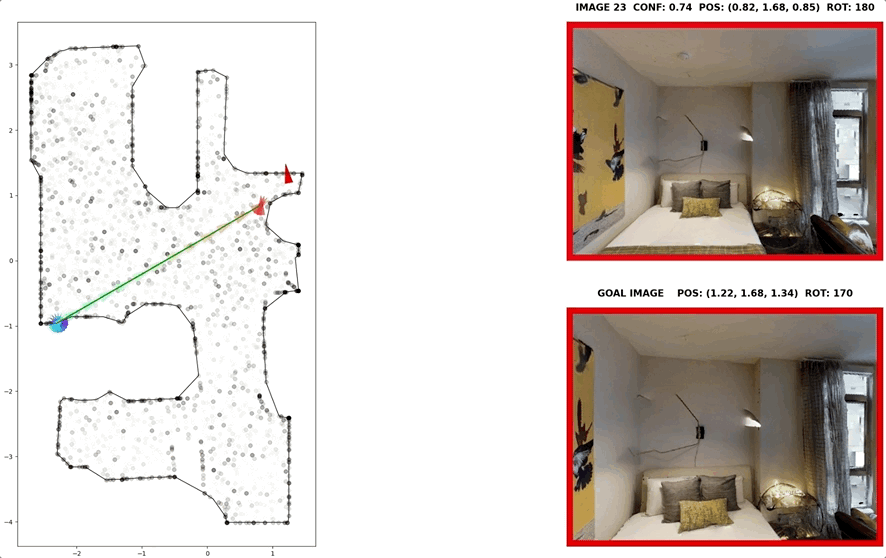
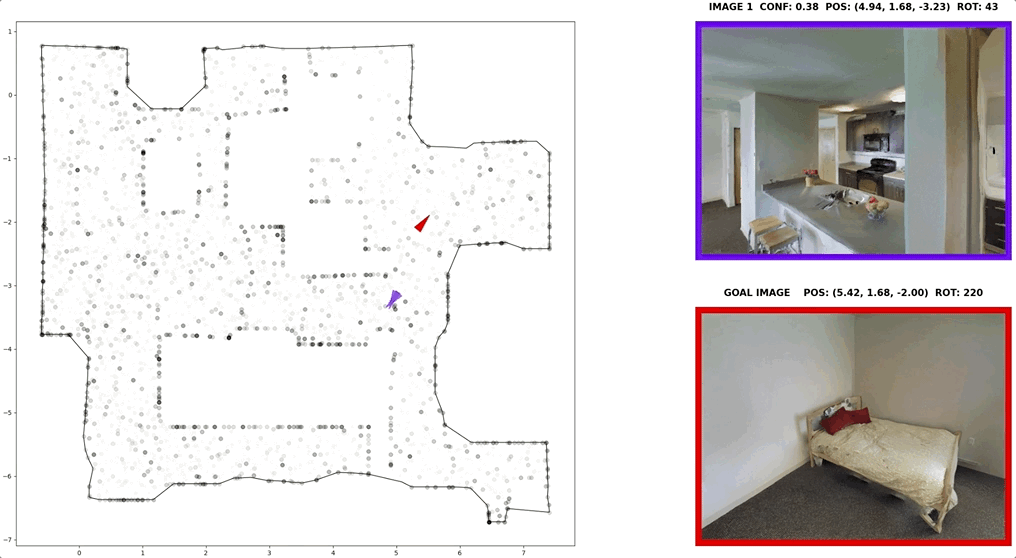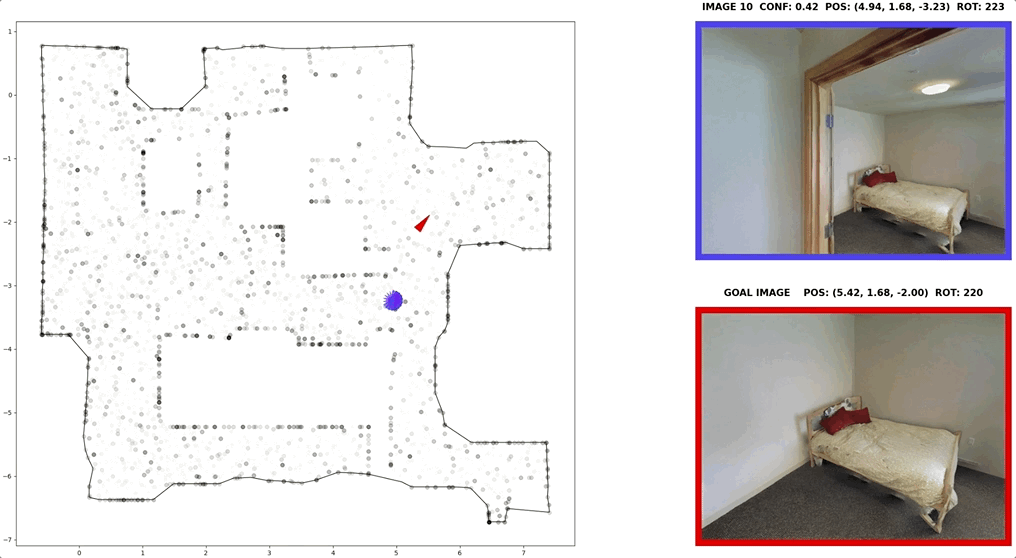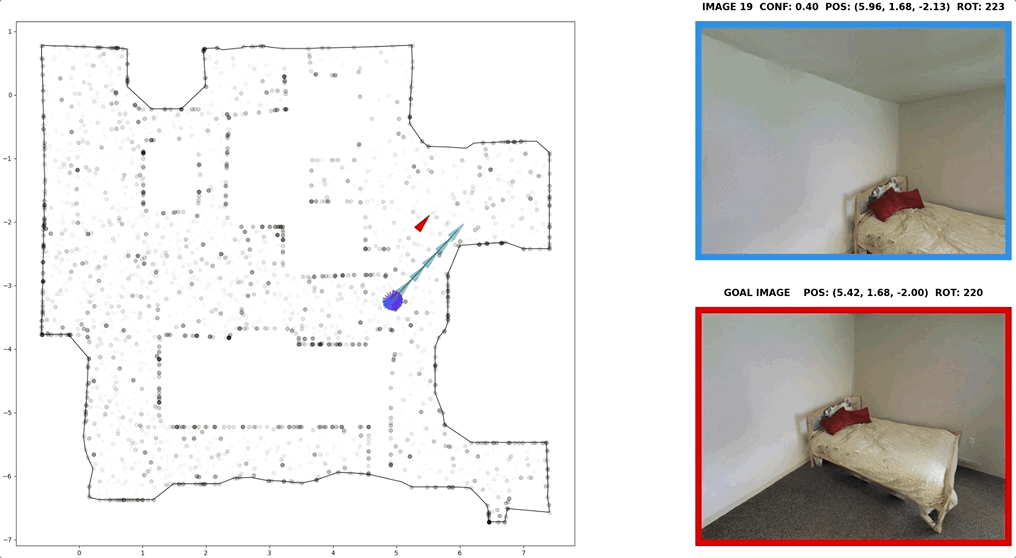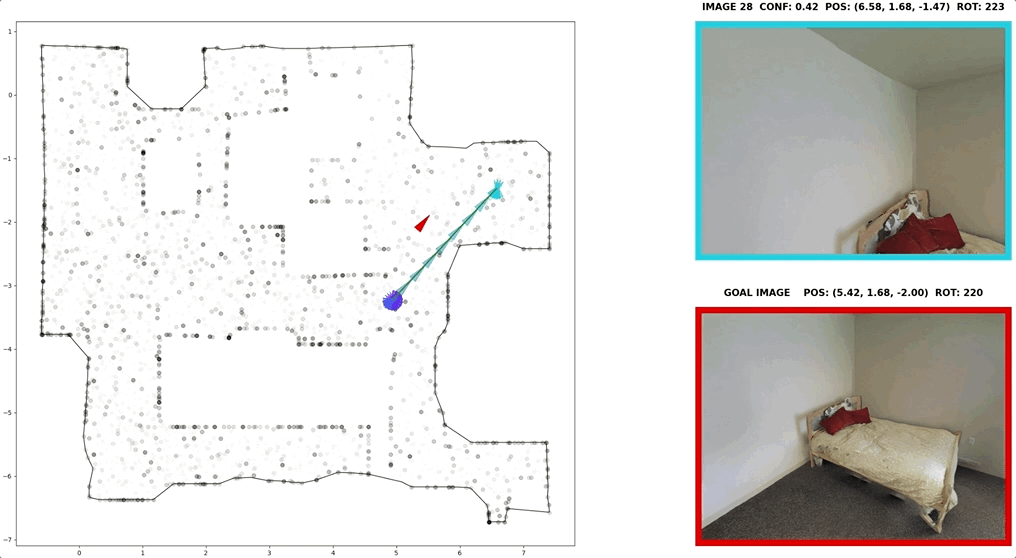
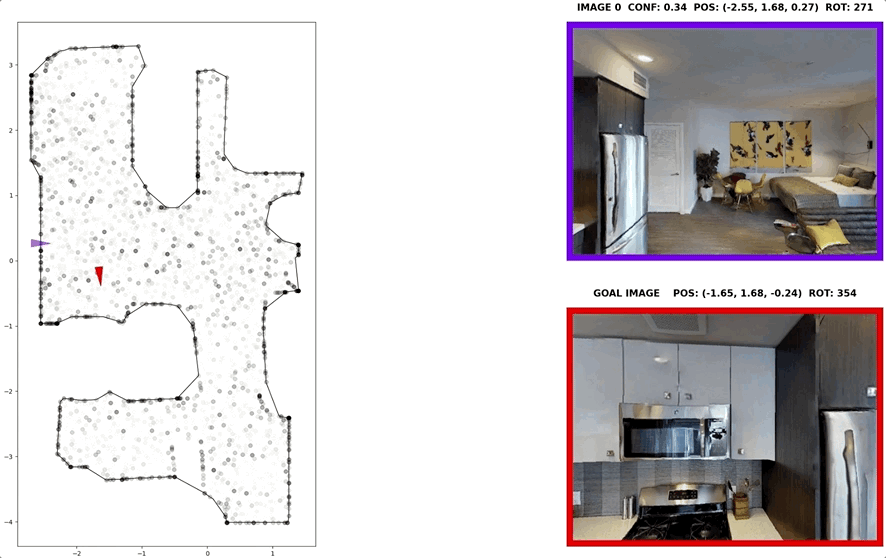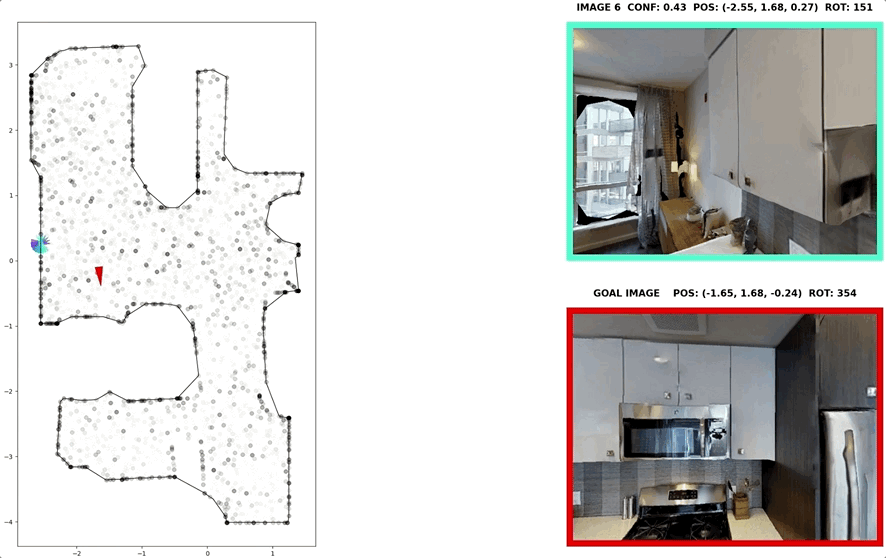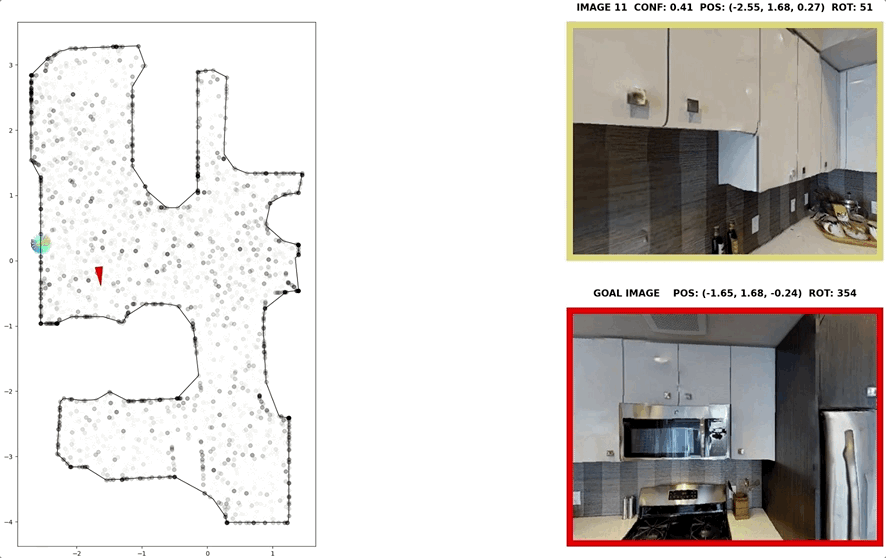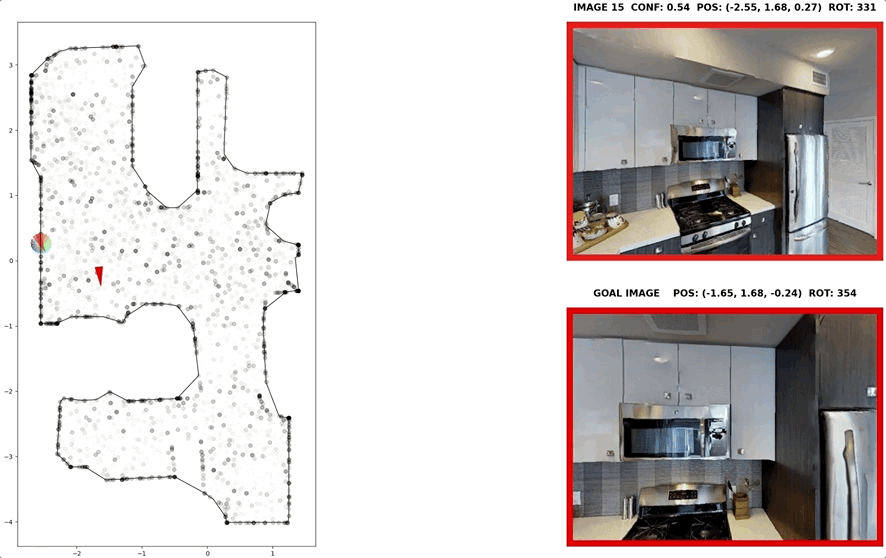
In visual navigation, one powerful paradigm is to predict actions from observations directly. Training such an end-to-end system allows representations that are useful for downstream tasks to emerge automatically. However, the lack of inductive bias makes this system data-hungry. We hypothesize a sufficient representation of the current view and the goal view for a navigation policy can be learned by predicting the location and size of a crop of the current view that corresponds to the goal. We further show that training such random crop prediction in a self-supervised fashion purely on synthetic noise images transfers well to natural home images. The learned representation can then be bootstrapped to learn a navigation policy efficiently with little interaction data.
@article{wang2022visual,
title={Visual Pre-training for Navigation: What Can We Learn from Noise?},
author={Wang, Yanwei and Ko, Ching-Yun},
journal={arXiv preprint arXiv:2207.00052},
year={2022}
}